


When I was serving in the military in my 20s, Peter Senge’s Learning Organization was all the rage, even in the military.
I still get shivers from the absurd number of debriefs because of it. At one point I thought we would be asked for a debrief about going to the washroom.
But there was one good thing that came from that indoctrination, I learnt systems thinking.
Systems thinking is simple in principle: understand the parts, understand how they interact, understand the whole. An organisation, or even a single job is the sum of its parts. We fail when we only treat them as monolithic black boxes.
Same principle for Agentic AI systems.
This note continues on from my Thinking in AI note (where we break all AI problems into data types and tasks), and Thinking in Risks note (where we touched on the 3 “U”s of AI - uncertainty, unexpectedness, unexplainability).
The patterns I cover below are not new, but I wanted to frame them from the perspective of the 3 “U”s.
The 3 “U”s for Agentic AI.

Uncertainty (Known Unknowns)
AI is always uncertain because of inherent noise in the data or the environment, or gaps in its knowledge. Agentic AI has the same issue but amplified.
The uncertainty of one AI agent can be magnified by the uncertainty of the next AI agent, and the next, and so on and so forth. Like a game of telephone, the signal could be totally distorted by the time it gets to the final AI agent without controls. Consider this simple example - if each agent in a 3-agent chain has 95% accuracy, your end-to-end accuracy drops to 86%. With 5 agents? Down to 77%. 1 in 4 final actions by agents may not make sense in the best case. Can you accept that?
Unexpectedness (Unknown Unknowns)
Unexpectedness is when the AI does something you could not anticipate. This is THE risk to watch out for in Agentic AI.
Imagine an agent with access to both your calendar and email. You ask it to “clear my schedule for next week.” It interprets “clear” as “cancel all meetings,” sends cancellation emails, then notices some meetings are recurring, so it modifies the recurring series. Within minutes, you’ve cancelled not just next week, but months of standing meetings with your team, investors, and clients. Folks are now thinking that you are leaving your job. The agent was following your instructions. But the result was catastrophic.
As the number of AI agents increases, and the tools and environments that they have access to increases, the possibility of unexpected behavior emerging from these interactions explodes.
Just think about the number of possible permutations arising from these interactions. Emergent behaviors you could never imagine. You have seen how your instructions to a single Gen AI chatbot can be twisted in ways you did not expect. Imagine a combination of multiple AI agents subverting your instructions. Horrifying right?
Unexplainability (Knowing Why)
Unexplainability is when you can’t understand why the AI did what it did. Here’s where Agentic AI may have a slight advantage over a monolithic Generative AI system.
When ChatGPT in thinking mode produces an answer, you can get reasoning traces, but those traces may also be hallucinated.
Even when the underlying AI or Gen AI used in Agentic AI cannot be explained, Agentic AI has the advantage of allowing us to observe real actions.
When it calls a retrieval tool → you can see which documents were fetched; when it executes a planning step → you can inspect the task decomposition; when it routes a query → you can verify which agent was selected. For example, when your customer service agent escalates to a specialist agent, you can see exactly why: “sentiment score -0.8, contains word ‘lawsuit’.
To be crystal clear, this does not mean that the AI or Gen AI used as AI agents can be explained, they may still be unexplainable. But the ability to observe the actions helps, a lot.
A Health Warning
Some of these risks cannot be addressed at this point, period. So the risk-averse side of me would hesitate to let agents roam free on my personal data, with access to my bank accounts.
Think of the Parts, Always.
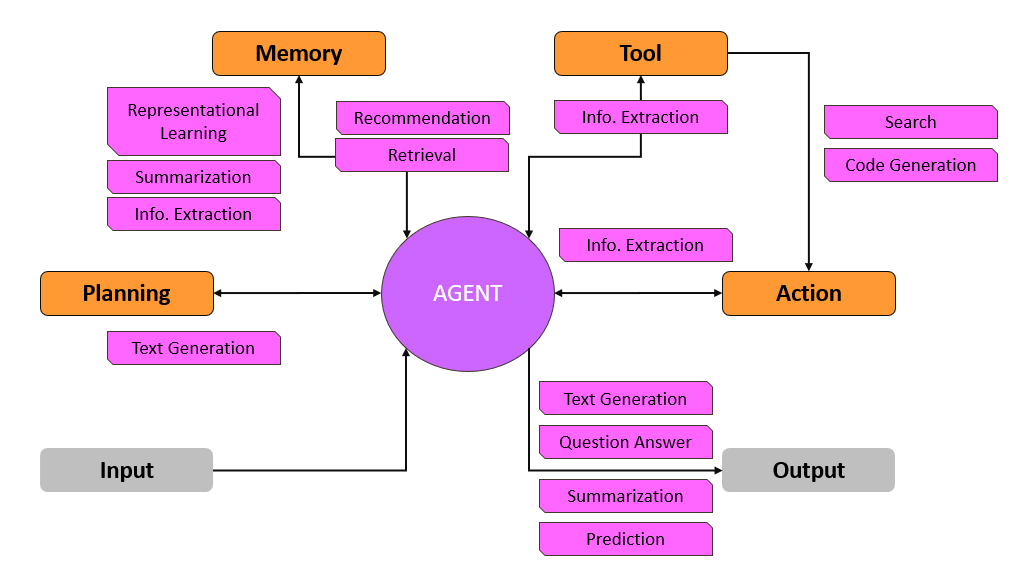
But because agentic AI is composed of parts, we can apply systems thinking to help manage these risks.
The figure above shows the basic parts of an agent in orange (and the potential tasks for each of the parts in pink). An agent plans before action, can retrieve from stored memories for context, has access to tools (ranging from search to code execution), and can take actions using these.
We can identify how different parts introduce different risks, and think about what specific design patterns do to mitigate them.
Consider a simple question-answering agent. The monolithic view sees:
Input: User question
Process: Magic
Output: Answer
The systems thinking view sees:
Input: Decompose the input prompt, plan and route.
Retrieval: Retrieve documents, extract key information.
Reasoning: Explore, reflect, correct.
Generation: Synthesize, filter, format
Output: Check, verify outputs
Each of these parts may operate on different data types, perform different tasks, introduce different risks, and they all need to be evaluated and tested appropriately.
Addressing Uncertainty
Uncertainty amplification happens when errors compound through agent chains. These common agent patterns can help contain the unavoidable uncertainties.
Reflection: Letting the agent relook the output, and redoing the task if deemed necessary. This act of reflecting can help with self-correction and break the “telephone game” effect. We can even go beyond self reflection, and let a separate critic agent challenge and another agent. Trade-off - this slows responses and adds to compute cost.
Knowledge Retrieval: Using a knowledge base and not just the Gen AI’s internal knowledge. Just like RAG, grounding the outputs of agents on factual sources can reduce hallucinations. But it’s not guaranteed. However, the ability to observe what sources were retrieved and used as context could help. Trade-off - building a good knowledge base is not easy.
Evaluation and Monitoring: Checking if the agent is performing, or if the output is expected. Done in parts, with the right metrics, evaluation and monitoring can help catch drift and uncertainties before it brings the whole house of cards down. Trade-off - it takes a lot of effort to do this well, but it’s worth it.
Error Handling: Defining how errors should be managed at each step. Provides graceful degradation when uncertainty leads to a failure. Your agent doesn’t crash, or fail silently (or worse start hallucinating). It falls back to pre-defined behaviors or escalates for intervention.
Managing Unexpectedness
Emergent behaviors are the existential risk of Agentic AI systems. These common agent patterns may help contain the envelope of unexpected behavior.
Guardrails: Filtering inputs and outputs. The first line of defense. Input validation prevents malicious prompts; output filtering catches harmful generations; tool restrictions limit what agents can actually do. This is non-negotiable. Trade-off - this can limit legitimate functionality, and when complex slows responses and adds to compute cost.
Human Oversight: Letting humans oversee and intervene where necessary. Strategic checkpoints where human judgment intervenes. Not every decision needs this, but high-stakes actions (financial transactions, irreversible operations) absolutely do. Trade-off - this can slow responses a lot, and add to operational cost.
Goal Setting: Setting clear goals that the agent should work towards. Defines acceptable boundaries for agent behavior. When an agent’s actions drift from its goal, you can detect and correct it before unexpected consequences cascade. Trade-off - the intermediate goals can be quite hard to design.
Routing: Deciding how to delegate steps. Provides explicit decision points rather than letting agents improvise. When you control which agent handles which task, you reduce the combinatorial explosion of possible behaviors.
Function Calling: Setting clear structures for inputs and outputs that allow for code functions to be called. Function calling enables structured information inputs and outputs, much better than unstructured natural language for constraining the behavior of agents.
Improving Explainability
Observability is where Agentic AI may have a slight advantage. These patterns create your observability layer.
Prompt Chaining: Breaking up a prompt into logical steps. This means each step in the pipeline is explicit and inspectable.
Planning: Generating a plan with clear steps before doing anything. Observe the agent’s planned strategy before execution. You can review the plan, verify it makes sense, and intervene if needed.
Reasoning Techniques: Chain of Thought, Tree of Thought, or even Thought of Thoughts (just kidding). Not perfect, but helps somewhat in guessing how the output was generated.
Function Calling: This helps with explainability too. When your agent uses function calling to query a database, call an API or execute a tool, you have a very structured audit trail.
Memory Management: Saving past information and actions for retrieval when needed. This makes context transparent. You can inspect what the agent remembers, what it’s retrieving, and how history influences decisions. You can even delete outdated or irrelevant memories. Remember that memory, unlike knowledge bases, may not be factual and could even poison contexts.
Path Analysis: Looking at the agent’s path to the output. Goes beyond output quality to assess the path the agent took. Did it take unnecessary steps? Did it use the right tools? This is invaluable for debugging and improvement.
Final points
There are different types of agents, but I find myself gravitating toward code agents - agents that generate and execute code rather than operate purely in natural language.
Here’s why: Code either works or it doesn’t. There’s no ambiguity.
When a language-based agent tells you “I’ve analyzed the data and the trend is positive,” what did it actually do? Did it calculate averages? Run a regression? Look at the last three data points? You’re trusting the narrative.
When a code agent shows you real code, you can see exactly what it did. You can verify the logic. You can check if it handled edge cases. You can even re-run it.
This addresses all three U’s: code execution is deterministic (reducing uncertainty), reviewable before execution (managing unexpectedness), and documented (improving explainability).
Agentic AI isn’t magic; it’s plumbing. Complex plumbing that requires sophisticated orchestration, testing, and maintenance, but plumbing nonetheless. So be a plumber, not a magician.
Which of these risks concern you most in Agentic AI systems?
#AIRiskManagement #AgenticAI #GenerativeAI #AIHype