

In previous notes in this series on Thinking in AI, we looked at the role of data and tasks when thinking about AI in Introduction to Thinking in AI; intuitively understanding AI models in Deconstructing AI: An AI Model is just Math; and taking a fundamental look at data types and tasks in Focusing on Data Types and Focusing on Tasks as Building Blocks.
Now let’s see if we can apply concepts from these notes to Generative AI, particularly Large Language Models (LLMs).
Two Patterns for Using LLMs
Let’s start with 2 common patterns of use.
The Chat Interface
Let’s start with the first pattern of use - the chat interface.
The chat interface, popularized by OpenAI's ChatGPT, has become the de facto interface through which we interact with most Generative AI services. Its popularity should come as no surprise, due to its intuitiveness and low barrier to entry. Asking a question and reading the response from a chat interface requires no technical understanding or skill.
Using Generative AI as a monolithic general-purpose tool through the chat interface for solving any problem could be viewed as the antithesis of what we have been discussing. Why bother to deconstruct a problem and map the problem to relevant data types, tasks and models when one can simply pose any problem as a query through the chat interface to the LLM and get a ready response.
For anyone who has used more than one Generative AI service with the same underlying LLM model (say the same GPT-4o model in ChatGPT and Perplexity), we would have observed significant differences in responses for an identical query. Variations in model parameters, such as the temperature setting that controls the uncertainty of generated outputs, or the inherent randomness (or stochasticity) of different runs of the LLM model do not fully explain the differences. The deceptively simple chat interface masks a much more intricate orchestration of tasks, which can differ significantly across different Generative AI service providers. Understanding this can allow us to use these services more effectively. Unfortunately, this has become more complex and less transparent over time.
Prompt Engineering
Another pattern of use relates to prompt engineering. The name of this pattern is a misnomer as it usually involves a trial and error process rather than systematic engineering (though there are exceptions, for example when one uses auto-prompt engineering tools such as DSPy). Prompt engineering usually involves manual adjustments to the prompt instruction to get a “good” response from the Generative AI model.
Again, the popularity of prompt engineering should come as no surprise, due to its intuitiveness and low barrier to entry. When a few quick adjustments to a text instruction can yield the desired outcome, the need to engage in a more deliberate process of identifying the underlying data types and decomposing the problem into specific tasks can seem superfluous. If the LLM can be coaxed into summarizing a page of text with a simple prompt instruction, why bother to explicitly define a summarization task or consider the nature of the data it needs to operate on?
But, this trial-and-error approach, while easy to get started with, may not be the most appropriate if our aim is to build a scalable solution. Just because we can tweak or tune a prompt instruction or multiple prompt instructions to get the right answer for one or more examples for a proof of concept solution doesn't mean we've built a reliable solution. In fact, I would argue that this pattern is way worse than the chat interface pattern as it gives a false sense of comfort. If the problem changes even slightly, or if we ask a new, unseen question, this carefully designed prompt might not work. The impressive proof of concept AI solution may just be a brittle band-aid fix.
Data Types and Tasks in Generative AI
Now let’s examine one of the most common Generative AI archetypes, Retrieval Augmented Generation (RAG) and its extension, GraphRAG, to illustrate how they can be viewed through the lens of data types and tasks, and see how they can improve design (for greater clarity, reality checks and tool selection), evaluation, as well as explainability.
Retrieval Augmented Generation (RAG)
RAG offers a number of advantages: it allows LLMs to provide more up-to-date responses (even after the training cut-off date) without training or fine-tuning; it grounds the LLM by providing contextual information relevant to the use case; it allows for better explainability by citing the information used to generate the response. The basic idea is a simple one - the RAG first retrieves pertinent information from a knowledge base and provides such information to the LLM as context for generating an answer.
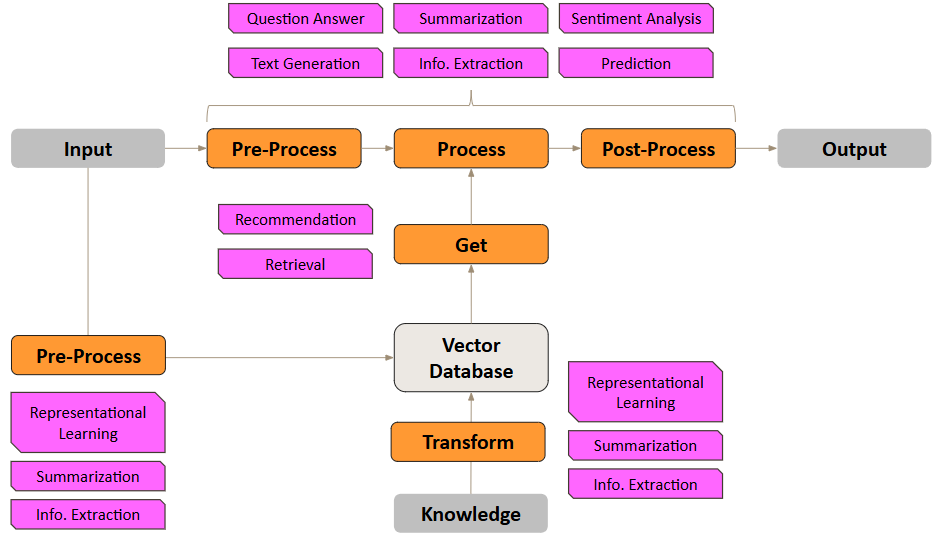
Let's break down the process shown in the figure above to take a closer look at the role of data types and tasks for Generative AI. I have deliberately labelled the key steps in the diagram above in a generalized manner to avoid limiting the interpretation to a specific architecture. This allows us to view various Generative AI workflows through this common structural lens.
Pre-Process Input
Event: User types in query or request.
Data Types: Usually text or image (if LLM is multimodal). But could also be tables, or even graphs or networks. The output is a processed representation (e.g., refined text, vector, keywords, intent label).
Potential Tasks: To facilitate retrieval (Get) and improve text generation (Process):
Query Intent Prediction: Predict user's objective (asking a fact vs. asking for a summary).
Query Expansion/Refinement: Refine or expand the query to be more informative.
Query Keyword Extraction: Extract important words from the query.
Query Representational Learning (Embedding): Transform query into a representation (numerical vector) that facilitates semantic similarity comparisons with information in the knowledge base.
Query Summarization: Condense long user inputs or prior conversation into a concise summary that captures the essential information.
How it helps: Thinking about these data types and tasks helps design more efficient flows (e.g., different handling of text vs. tabular data, questions vs. summarization requests), evaluate if the model understood the query correctly (evaluation), and provide greater transparency and explainability on the nature of data flowing to the next step.
Transform Knowledge
Event: Ingest and prepare background knowledge sources for retrieval (Get).
Data Types: Input can include text documents (plain text, PDF, HTML); tables (from databases); semi-structured data (JSON), images, potentially even graphs or networks. Output consists of processed data units like text chunks, representations (numerical vectors that capture semantic meaning), and associated metadata (e.g., keywords, dates, document tags).
Potential Tasks: To prepare diverse data types for efficient and relevant retrieval:
Chunking: Breaking down large documents or data structures into smaller, semantically meaningful units for embedding and retrieval.
Information Extraction: Identifying and extracting key entities, relationships, or metadata from the source data to enrich the chunks.
Representational Learning (Embedding): Converting processed chunks (text, image features, table representations) into numerical vectors that capture semantic meaning.
Indexing: Organizing vectors and metadata in a specialized database (e.g., vector store, keyword index) for fast lookup.
How it helps: Makes explicit the design choices for handling different source data types and preparing them for search (e.g., chunking method, embedding model choice). Allows evaluation of the preparation quality (e.g., embedding performance) and gives transparency into how knowledge is structured and stored for retrieval.
Get Relevant Information
Event: Searching the prepared vector database using the processed user query to retrieve relevant information.
Data Types: Input is the processed query representation (e.g., vector, keywords). Output is a ranked list of relevant context chunks (which could be text snippets, table fragments, image references, graph nodes/edges, etc.).
Potential Tasks: To find the most relevant pieces of information from the vector database to address the user's query:
Vector Similarity Search: Finding indexed chunks whose vectors are semantically closest to the query vector.
Keyword Search: Matching specific terms in the query against indexed text.
Hybrid Search: Combining vector and keyword search techniques.
Re-ranking: Applying secondary scoring to the initial retrieved set to improve relevance order.
Filtering: Excluding or including chunks based on metadata (date, source, permissions).
How it helps: Allows deliberate design of the search or retrieval strategy (algorithms, parameters like 'k', filtering rules). Enables isolated evaluation of retrieval effectiveness (using metrics like Recall, Precision, Mean Reciprocal Rank) and provides transparency into exactly what information was fetched and passed to the LLM as context.
Process Query and Context
Event: LLM generates a response using the user's query and the retrieved context.
Data Types: The augmented prompt, typically text combining the original query with the retrieved context chunks (which might represent text, tables, etc.). Output is the text response from the LLM, which could be unstructured text, or information in a structured dictionary format.
Potential Tasks: To generate a coherent, relevant, and grounded answer based on the provided query and context:
Grounded Text Generation: Creating narrative text that primarily uses information from the query and context.
Contextual Question Answering: Formulating a direct answer to the query using only the provided context.
Summarization: Generating a concise summary of the key information within the retrieved context relevant to the query.
Grounded Reasoning: Making logical deductions or inferences based strictly on the information present in the context.
Structured Information Generation: Generating output that conforms to a specific format or schema (like JSON or XML) based on the input and context, useful for structured data extraction or downstream automation.
How it helps: Focuses design efforts on crafting effective prompts that guide the LLM on how to use the context and select LLMs suited for the task. Enables evaluation of the generated output's quality given specific context (e.g., faithfulness, relevance) and offers transparency into the LLM's process, helping identify issues like hallucination or poor context utilization.
Post-Process Generated Output
Event: Refining the raw output from the LLM before presenting it to the user.
Data Types: Input is the generated text response. Output is the final, potentially formatted text (including structures like tables or lists rendered from Markdown), possibly annotated with citations.
Potential Tasks: To enhance the clarity, trustworthiness, safety, and usability of the final response:
Citation Generation: Linking specific statements in the response back to the source context chunks.
Filtering: Reviewing and filtering the output for harmful, biased, or non-compliant content.
Fact-Checking: Optionally verifying claims made in the generated text against the retrieved context.
Answer Synthesis: Combining outputs if multiple generation steps or checks were involved.
How it helps: Allows the design of robust user experience features (citations, safety filters). Enables targeted evaluation of these specific additions (e.g., citation accuracy, filter effectiveness). Provides transparency by separating final processing and safety checks from the core LLM generation step.
GraphRAG
The GraphRAG archetype presents an interesting evolution, illustrating how changing the underlying data representation—from isolated text chunks to interconnected graphs or networks—can significantly alter the process and potentially improve the relevance and coherence of generated responses. A knowledge graph represents information as nodes (entities, concepts) and edges (relationships between them).
There are differences across all steps, e.g., focusing on named entity recognition (NER) when pre-processing query inputs, methods to provide graph or network structures as context during processing, or as citations during post-processing, but we focus on the steps relating to the transformation of knowledge and getting relevant information, which are the key features of GraphRAG (as compared to vanilla RAG).
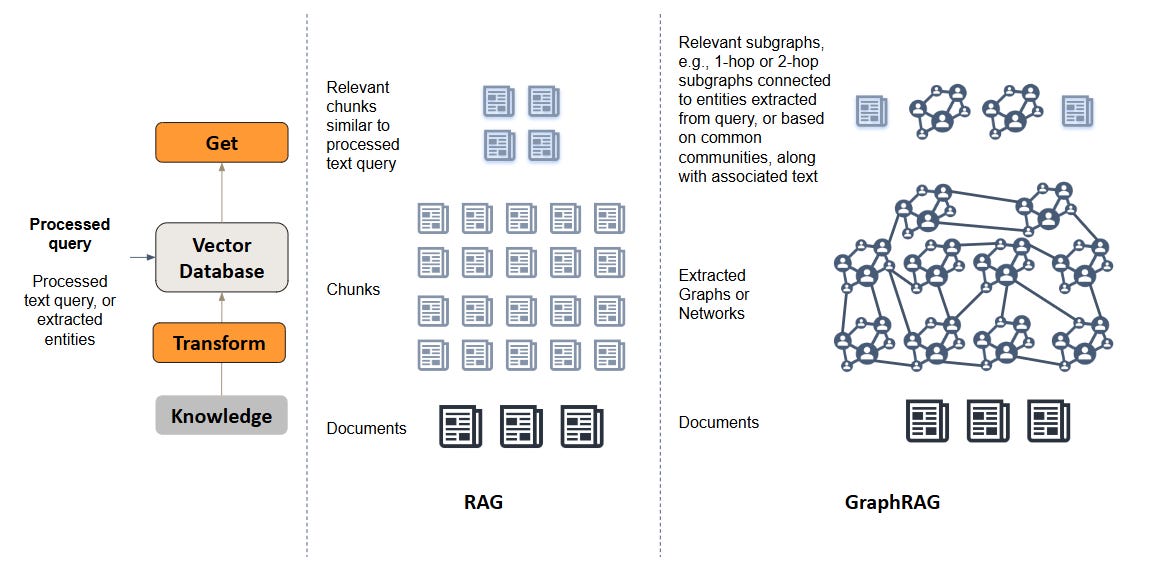
Transform Knowledge
Event: Ingest and transform background knowledge to a graph or network.
Data Types: The transformation of text data to graphs or networks is a key step. We go from text information to knowledge graphs, comprising nodes (entities), edges (relationships). Representations or embeddings for nodes, edges, or subgraphs may also be generated and stored.
Potential Tasks: To represent knowledge:
Knowledge Graph Construction: Using techniques like NER and relation extraction to identify nodes and edges from source data.
Subgraph Extraction or Community Detection: Instead of chunking, extract subgraphs or detect communities in graphs or networks.
Representational Learning: Create vector representations for nodes, edges, or sub-graph patterns.
Graph Enrichment: Adding properties, metadata, or text descriptions to nodes and edges.
How it helps: Focuses on capturing rich relationships via the graph construction process. Evaluation can involve graph quality metrics (e.g., density, coherence) and performance when extracting entities/relations. Transparency comes from the explicit, queryable structure of the knowledge itself.
Get Relevant Information
Event: Searching the knowledge graph to retrieve relevant information, typically via entity to entity relationships, or using subgraph or community structures to retrieve a relevant subgraph or set of interconnected information.
Data Types: Input includes the processed query representation (which can include both entities, as well as text representations). Output is typically a subgraph (a collection of relevant nodes and edges), along with the associated attributes and text.
Potential Tasks: Semantically similar information retrieved using the usual RAG process is combined with contextually relevant information obtained by exploring connections within the graph:
Graph Traversal: Navigating the graph by following edges from starting nodes (e.g., finding neighbors, exploring paths between entities).
Subgraph Extraction: Identifying and extracting a relevant portion of the graph based on the query and traversal results.
Community Detection: Identifying densely connected clusters of nodes (communities) within the graph that relate to the query entities.
How it helps: Retrieval leverages the explicit relationships in the graph or network, potentially uncovering connections missed by semantic similarity alone. This involves using graph search algorithms (traversal, community detection). Evaluation can measure the relevance of the retrieved subgraph/paths/communities. Transparency or explainability are improved through the retrieval paths or community structures.
Conclusion and implications
Viewing the generalized RAG through the explicit breakdown of data types and tasks offers significant advantages. From a design perspective, it promotes modularity, allowing deliberate choices for each component. While some modules can leverage on Generative AI, other modules can use simpler AI models or even rule-based algorithms. This can reduce uncertainties. From an evaluation perspective, it enables focused testing at each stage. For greater explainability, the decomposition enables one to examine the intermediate steps and results, making the system's behavior easier to understand. When we view these systems not as monolithic black boxes but as orchestrated collections of specific data types being processed by distinct tasks, their inner workings become far less opaque.
GraphRAG is a prime example of how a deeper appreciation for different data types (text transformed into graph data) within a particular AI task (retrieval)—can lead to potentially more reliable solutions.
This data type and task-based perspective, which has been the cornerstone of our Thinking in AI series, is more than just an analytical framework. It steers us away from the extremes of building unmanageable monoliths or hyper-specific, brittle solutions built using ad-hoc tuning.